Un algorithme est une procédure codée, destinée à transformer les données en fonction de calculs spécifiés. Cette procédure se rapporte à un problème spécifique : à chacune de ses étapes, ce problème doit être résolu, et cela suppose qu’il y ait un état initial et un état fini (Gillespie, [1]). Une définition plus courte de l’algorithme est plus largement répandue est celle d’une suite finie d’instructions destinées à résoudre un problème (Steiner, [2]). L’algorithme, métaphore de la recette de cuisine [3] ou du programme d’une machine à laver, trouve ses origines dans l’Antiquité. L’algorithme d’Euclide (-300 AJC), l’un des premiers algorithmes connus (et encore utilisé de nos jours), permet de déterminer le plus grand commun diviseur de deux entiers naturels. Le terme « algorithme » provient du nom latinisé d’un mathématicien perse (-9 AJC), Ali-Khwârizmi.
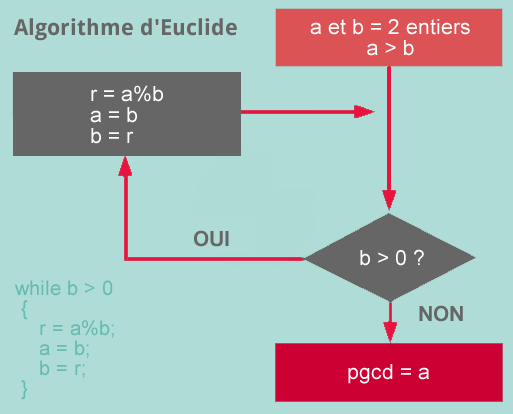
Quantité d’algorithmes ont essaimé depuis, mais leurs premières formalisations remontent à 1936, avec la machine d’Alan Turing. En 1943, Kleene développe les théories algorithmiques, décrivant des procédures se succédant en prenant un chemin différent selon que la réponse à la question posée soit « oui » ou « non ». Pour Gillespie, un ordinateur doit se concevoir comme une machine algorithmique qui héberge et lit des données. La mise en œuvre d’un algorithme implique nécessairement un langage de programmation. Si les promesses algorithmiques reposent sur leur crédibilité, leur fiabilité et leur neutralité, il reste illusoire de croire que le code s’écrit en dehors de toute influence humaine. « On a toujours besoin d’une intervention humaine. La culture algorithmique a besoin d’humains. L’automatisation ne nous transforme pas en robots : elle rend les choses plus faciles », indique Gillespie. Avant d’être technique, le code est donc social.
C’est ce que soulignent les « software studies », qui proposent un cadre théorique (et critique) pour l’étude des logiciels. Dans ses travaux, Lev Manovich (« Le langage des nouveaux médias », « Software takes commands ») [5] [6] a mis en avant les caractéristiques intrinsèques des nouveaux médias : représentation numérique, modularité, automatisation, variabilité et transcodage culturel. Les programmes informatiques créent de nouvelles formes culturelles, écrit-il, tout en modifiant des formes existantes, à l’image d’un DJ dans son rôle de « remixeur ». Aussi, analyse MacKenzie [7], le logiciel n’est pas seulement un processus, il s’agit d’un objet culturel et social. L’algorithme, cadré par le temps et l’espace de la computation, est une procédure formelle qui n’est pas neutre car elle est le fruit d’une l’activité productive : « Il – l’algorithme – transporte l’espace social dans les réseaux logiciels. »
Par ailleurs, Lawrence Lessig [4] postule une gouvernance du code dans tous les aspects de la vie humaine, une gouvernance opaque dont il faut avoir conscience. « Le code régule. Il implémente – ou non – un certain nombre de valeurs. Il garantit certaines libertés, ou les empêche. Il protège la vie privée, ou promeut la surveillance. Des gens décident comment le code va se comporter. Des gens l’écrivent », souligne-t-il.
Une apparente neutralité
A la question de la qualité du code s’ajoute celle des données dont il se nourrit. Cet aspect est crucial dès lors que les données sont susceptibles d’impacter le monde réel : des données empiriques ne sont pas figées une fois pour toutes dans le temps car elles sont le résultat de mesures et d’observations du monde à un instant T [8]. Les données sont-elles à jour, fiables, complètes, contrôlées en amont ? La source est-elle bien identifiée ? Ces questions ne sont pas triviales et se trouvent, elles aussi, à la source de la question fondamentale de la transparence [9]. Les enjeux sont ceux de la représentation sociale d’un monde en mouvement, de la manière dont les opinions se forgent et dont les actions se motivent : la caisse de résonance médiatique n’est pas exempte de conséquences.
L’apparente neutralité du code, qui va toujours résulter de choix humains, serait à mettre en parallèle avec ce fameux principe d’objectivité qui sous-tend l’activité journalistique. Nombre de travaux ont démontré qu’elle n’existe jamais totalement car, elle aussi, procède d’une succession de choix et véhicule les référents culturels et sociaux des journalistes. « Il est impossible de constater des faits sans les interpréter », relève Cornu [10]. « L’écriture de presse est travaillée par les tensions entre de la subjectivisation et de l’objectivation », notent Rabatel et Vileno [11]. Cet aspect est d’autant plus crucial qu’aujourd’hui, l’activité journalistique, qui n’est pas une activité commerciale comme les autres [12], n’est plus l’apanage d’une profession organisée : de nouveaux acteurs sont entrés dans la danse de l’information [13]. « Le journalisme prône l’éthique et la transparence », souligne Diakopoulos, « alors que les algorithmes sont souvent opaques » [9]. Mais il reconnaît que même si un code source était systématiquement diffusé, encore s’agirait-il de le comprendre, en raison du savoir-faire technique que cela nécessite. Si le code est opaque, c’est aussi parce qu’il donne de la valeur à son propriétaire. De plus, préviennent McCosker et Milne [14], le code est fragile et les logiciels ne sont pas à l’abri d’erreurs, de bugs ou de failles.
Références
[1] Gillespie Tartleton, Pablo J. Boczkowski, et Kirstn A. Foot. “Media Technologies: essays on communication, materiality, and society”. Inside Technology. MIT Press, 2014.
[2] Steiner Christopher. “Automate this: how algorithms took over our markets, our jobs, and the world”. Penguin Group US, 2012.
[3] Fuller, Matthew. “Software studies: a lexicon”. Mit Press, 2008.
[4] Lessig Lawrence. “Code Version 2.0”, Basic Books, 2006.
[5] Manovich Lev. “Le langage des nouveaux médias”. Les Presses du réel, 2010.
[6] Manovich Lev. “Software takes command”. Bloomsbury Academic, 2013.
[7] MacKenzie Adrian.“Cutting code. Software and sociality”, Digital Formations, 2006.
[8] Boydens Isabelle. “L’océan des données et le canal des normes”. Les Annales des Mines, (67) :22–29, juillet 2012.
[9] Diakopoulos Nicholas. “Algorithmic accountability”. Digital Journalism,2(4):1–18, 2014.
[10] Cornu Daniel. “Journalisme et vérité”. Labor et Fides, 2009.
[11] Rabatel Alain et Chauvin-Vileno Andrée. “La question de la responsabilité dans l’écriture de presse”, Semen, 22, 2006.
[12] Neveu Eric. “Sociologie du journalisme”. Collection Repères, La découverte, 2013.
[13] Mercier Arnaud et Pignard-Cheynel Nathalie. “Mutations du journalisme à l’ère du numérique : un état des travaux”. Revue française des sciences de l’information et de la communication, (5), juillet 2014.
[14] McCosker Anthony et Milne Esther. “Coding labour”. Cultural Studies Review 20.1:4, 2014.

 C’est d’ailleurs la logique adoptée par les réseaux sociaux qui ne proposent pas autre chose que les infos susceptibles d’intéresser l’utilisateur en fonction de son activité. Rien d’autre n’est dit à propos des processus de calcul sous-tendant cette logique. La métaphore de la boîte noire est régulièrement utilisée pour désigner l’opacité de ces systèmes, derrière lesquels se trouvent d’importants enjeux économiques. La gratuité de leur accès est une illusion : en économie, rappelle Perri
C’est d’ailleurs la logique adoptée par les réseaux sociaux qui ne proposent pas autre chose que les infos susceptibles d’intéresser l’utilisateur en fonction de son activité. Rien d’autre n’est dit à propos des processus de calcul sous-tendant cette logique. La métaphore de la boîte noire est régulièrement utilisée pour désigner l’opacité de ces systèmes, derrière lesquels se trouvent d’importants enjeux économiques. La gratuité de leur accès est une illusion : en économie, rappelle Perri