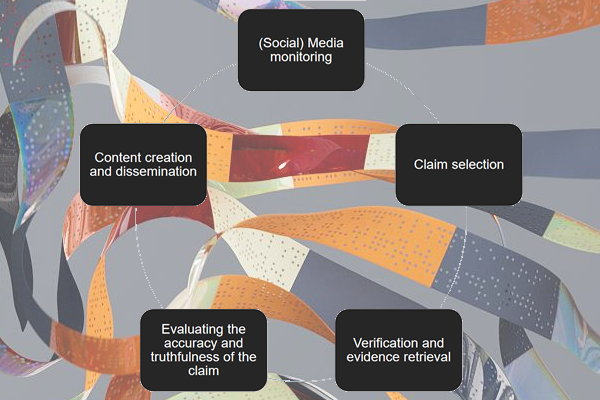
(Research note). This unpublished paper summarizes a part of a quantitative qualitative research led in the context of my master thesis in Science and Technologies of Information and Communication at the Université Libre de Bruxelles (2015), which was dedicated to the possibilities and limits of automated news. The proposed method consists in assessments trough metrics and human-based judgments used in the field of computational linguistics (metrics are commonly used in automatic translation). Here, judges were all journalists or writers. A corpus of twenty articles written by a software was first evaluated with the most common metrics used in computational linguistics. The experience then consisted in submitting to the human judges three samples of articles written by their peers and written through an algorithmic process. Without knowing the object of the experience, they were asked to evaluate the texts regarding quality criteriums as they were defined by Clerwall (2014). They were asked then to attribute to each text an author: a human or a software. In two cases out three, they did not recognize that the author was not a human being.
ASIA tools were used for the metrics assessments. Since then, I have developed my own tools which encompass several readability scores, iBLEU score and Levenshtein distance: https://ohmybox.info//linguistics/ This method is also used in the context of my PhD thesis but it was refined in order to fit to its purpose which is about the uses of news automation as a tool for journalists within their investigative or daily routines.
Click here for the available download link
NLGassessments